
推理性能飙升、成本结构重塑:ODCC 携手 NVIDIA、焱融等首发KV Cache评测,焱融 YRCache 交出“提速降本”双优答卷
随着大模型在企业场景中的快速落地,AI 推理系统正面临新的基础设施挑战。上下文长度不断增长、用户并发请求数量快速上升,使得传统 GPU 显存架构逐渐成为制约推理效率的关键瓶颈。如何通过系统架构优化释放算力潜力,保证推理性能与控制成本,已成为企业掘金 AI 商机的核心命题。
近日,开放数据中心委员会(ODCC)在 NVIDIA、美团、三星、Solidigm 等产业链领军企业支持下成立的 AI 存储实验室首次发布针对大模型推理关键制约因素——KV Cache 的专项评测结果。测试结果显示,焱融科技自主研发的 YRCache 推理存储系统实现了推理性能的数量级跃升与成本的革命性优化,为 AI 规模化落地提供了全新的“存储驱动推理”范本。
权威测试数据揭晓:TTFT 与 TPOT 降低97%,吞吐量提升 22 倍
作为国内专业的 AI 存储厂商,焱融自研的 YRCache 推理存储系统专为大规模推理设计,通过构建 GPU 显存、主机内存、本地 NVMe SSD 及 YRCloudFile 高性能分布式存储的多级缓存架构,旨在显著扩展 KV 缓存空间,打破显存限制。
本次测试在基于 NVIDIA 计算和网络平台的真实推理环境中进行,采用DeepSeek-R1等主流大模型,覆盖了中端 GDDR GPU 与高端 HBM GPU 两类算力节点,对比了在不同网络带宽配置(200Gbps / 400Gbps / 800Gbps)下,原生 vLLM 框架与集成 YRCache 后的系统性能。本次测试核心成果亮点显著:

-
推理性能全面数量级提升
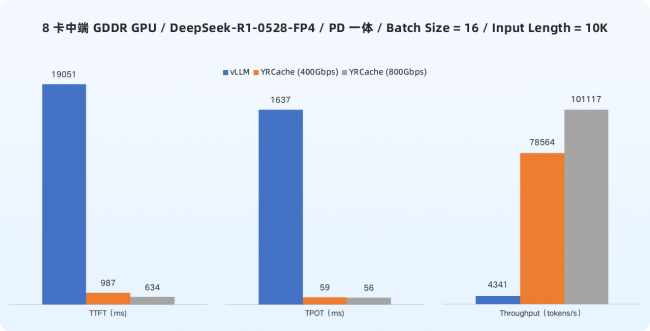
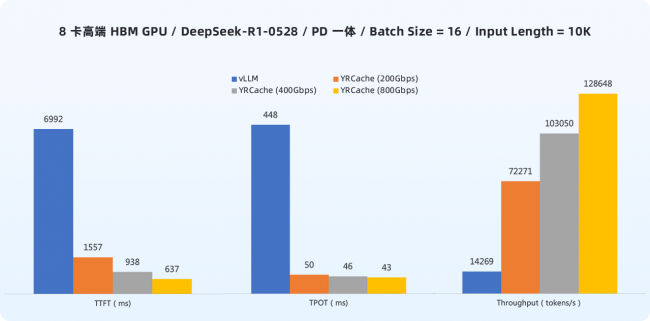
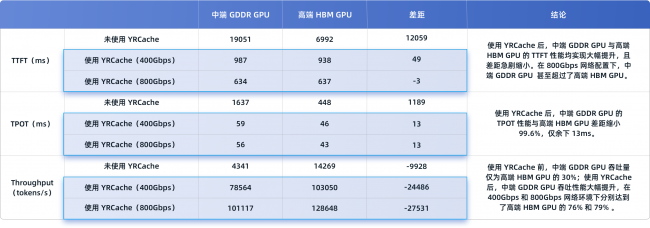
在 Batch 值为 16、输入长度 10K Tokens 的典型环境下,集成 YRCache 后,首 Token 延迟(TTFT)和单个 Token 生成时间(TPOT)可优化高达 97%,系统 Token 吞吐量最高提升 22 倍。这意味着用户将体验到“即问即答”的瞬时响应,长文档生成如丝般顺滑。同时,系统吞吐能力大幅增强,能够服务更多并发用户请求,单 token 成本也同比例降低。
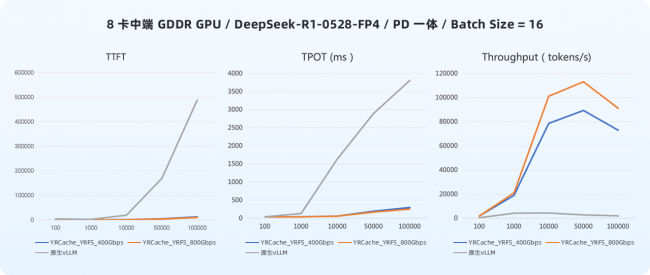
2. 长上下文场景表现稳定且性能提升增益放大
在模拟输入 Token 从 100 扩展至 100K 的测试中,YRCache 始终保持稳定性能优势,且随着上下文增长,其加速效果持续放大。这为企业在长文档分析、多轮对话等高负载任务中,提供了避免性能断崖的技术底气。
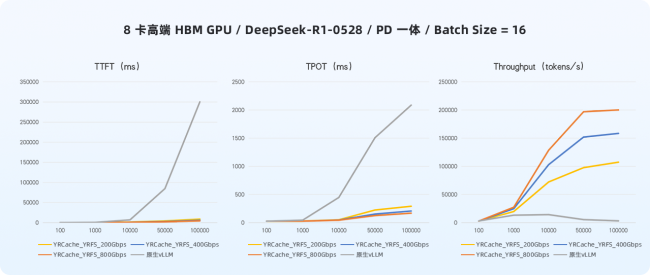
3. 中低配 GPU 推理性能接近追平高配卡,推理成本实现结构性优化
测试揭示了一项更具战略价值的成果。在YRCache加持下,中端 GDDR GPU 服务器的综合推理性能,已大幅逼近甚至在某些维度媲美高端 HBM GPU 原生方案。具体数据显示,原生状态下中端 GPU 吞吐量仅为高端的30%,而在使用YRCache后,两者差距急剧缩小,可达到高端 HBM GPU 的 79%。
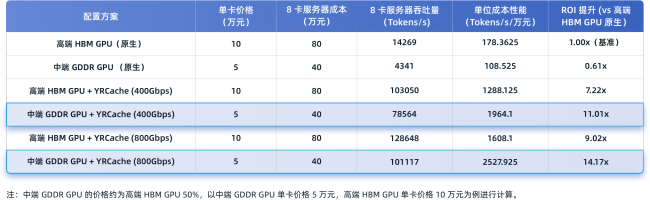
投资回报率(ROI)飙升14倍,重构 AI 推理经济模型
更直观的商业价值体现在投入产出比。从测试数据推算可看出,虽然原生状态下中端 GDDR GPU 表现不占优,但引入 YRCache 优化后,其 ROI 相比原生高端 HBM GPU 方案,在400Gbps和800Gbps网络环境下分别提升了 11 倍和14 倍。这意味着,在相同资金投入下,采用“中端GDDR GPU服务器 + YRCache”方案,能够带来远超高端HBM GPU原生方案的推理产出效率。这一突破重构了企业AI推理的成本结构——当推理成本的重心从依赖高端GPU转向依托存储技术创新,AI应用的盈亏平衡点将大幅下移。中小企业能以更低门槛部署高性能推理服务,而大规模AI企业则能显著优化TCO(总拥有成本),为更多创新场景打开经济可行性大门。
迈向“存储驱动推理”的新范式
本次 ODCC 的首发评测,不仅验证了焱融 YRCache 的技术实力,更标志着“以存促算、架构降本”的AI推理新路径的可行性。作为 ODCC AI 存储实验室的重要实践,该测试为行业提供了可量化、可复现的技术参考,推动AI存储技术向标准化、规范化迈进。
ODCC AI 存储实验室表示,将持续推进 KV Cache 系列测试,深化“部件—系统—应用”全栈协同。焱融科技也强调,YRCache 同时支持 PD(Prefill-Decode)分离等下一代推理架构,持续以“数量级性能提升+颠覆性成本优化”的双重能力,助力企业在 AI 规模化落地的浪潮中以更低成本、更高效率抢占先机。










