
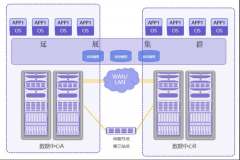
构建高可用IT基础架构 保证核心业务系统连续性
利用VERITAS Storage Foundation,我们可以创建任意一个逻辑卷(Volume)供业务主机使用,实际上是由个完全对等的,容量相同的磁盘片构成,两的个磁盘片上的数据完全一样,业务主机对该Volume的任意修改,都将同时被写到位于生产中心和灾备中心的两个磁盘系统上。
采用这种方式,生产中心的磁盘阵列与同城容灾中心的磁盘阵列对于两地的主机而言是完全同等的。利用城域SAN存储网络和VERITAS Storage Foundation镜像功能,我们可以非常轻松的实现数据系统的异地容灾。并且消除了复制技术(无论是同步还是异步)的切换的动作,从而保证零停机时间,零数据损失的实现。
3 数据复制技术分析
数据复制技术主要集中在数据库、操作系统和存储硬件三种技术上,每种技术都有其适用的范围,下面对各种技术对性能的影响做一个简单分析。
3.1 性能分析
考察容灾系统对业务系统性能的影响,主要从两个方面衡量:
一是CPU资源的消耗
二是I/O,特别是写操作的延迟效应。
ü CPU资源消耗
采用主机端的软件镜像技术,对CPU资源的损耗,实际上是微乎其微的。具体的事实可以通过简单的测试得到,可以设置这样一个测试,就一目了然了:
1)在测试系统上,往一个没有镜像的逻辑卷Copy一个大文件,察看CPU使用率;
2)在测试系统上,往一个有镜像的逻辑卷上Copy一个大文件,察看CPU使用率。
事实上,处理镜像需要的CPU时间是非常小的,原因是磁盘I/O操作的速度是毫秒(ms)级的,磁盘系统Cache I/O的速度是受限于光纤通道的100-200MB(8bit*10ns)带宽和距离(15公里 == 0.1ms)的,而相反的,高端主机总线的宽度一般是64-128Byte,甚至更高,主机CPU的处理速度更是在千兆的水平(ns级),所以I/O对主机CPU的消耗往往都是可以忽略不计的,万一说需要关心的话,也主要针对象RAID-5这样的技术(需要大量计算,从而消耗主机的CPU资源),而像镜像这样的技术,是几乎不需要消耗CPU时间的。
ü I/O的延迟效应(特别是写操作的延迟效应)
采用VERITAS Storage Foundation的镜像技术构建容灾系统,其对系统 I/O的延迟效应要小于任何一种数据复制技术,不管是基于磁盘系统的硬件数据复制技术,还是基于主机软件的数据复制技术,前面的部分已经做了阐述。
实际上,在整个容灾系统中,对业务系统的性能的影响最大的不是任何一种技术所产生的负面作用,而是“距离”,正如前面提到的,在Cache命中率较高的系统中,距离对写操作的影响较大,这和光的传播速度有关,光在150公里距离上的一个来回需要1ms,在15KM距离上一个来回需要0.1ms,我们列出一个对照表,供大家参考。本对照表不包含设备协议转换和光在光纤中的折射等因素。同时,我们知道,100MB光纤对应的速度是ns级的。
针对数据库日志复制技术,可以用如下的方式设置standby database数据库来达到不同的数据库数据保护级别:
1) Guaranteed protection:规定在修改主数据库时,至少有一个备用数据库有效。假如主(Primary Database)备(Standby Database)之间的连接中断,Oracle会通过中断主实例的工作来防止主备数据库之间的数据的不一致,保证无数据丢失。这种模式对数据库性能的影响较大。
2) Instant protection:规定在修改主数据库时,至少有一个备用数据库有效。与Guaranteed protection模式不同的是当主备数据库之间的连接中断时,允许主备数据库之间的数据的不一致,并当恢复连接后,解决数据不一致的现象。这种模式对主数据库的性能有较小的影响。
3) Rapid protection:主数据库的修改快速应用在备用数据库上。会出现数据丢失,但对数据库性能的影响小。
4) Delayed protection:主数据库的修改在延迟一定的时间后应用在备用数据库上。Rapid protection和Delayed protection模式即使在网络连接有效时,也允许主数据库与所有的备用数据库有数据分歧,数据的丢失量等同于主数据库联机重做日志的未归档数。这种方式对数据库性能的影响小。
在primary/standby配置下,所有的归档日志被发送到了standby 节点,这使standby 节点的数据保持着更新。但是,万一primary 数据库意外关闭,联机的日志将会丢失,因为它们尚未归档并发送到standby节点。这使得 primary 和standby 数据库之间会有一个差异。
DBA可以选择让LGWR在将重做日志数据写到本地磁盘的同时将数据发送到 standby 数据库。该功能称为standby零数据丢失(standby zero data loss)。这种方法从本质的角度讲提供了远程重做日志镜像,但带来的问题是会极大地损失性能。
3.2 复制效果分析
分析项目数据库复制存储硬件复制Symantec容灾方案
数据级容灾效果同步方式对生产中心的性能影响极大。因此基本采用非同步方式,RPO、RTO都不为零,需要停机时间,数据损失量为一个Archive Log 的数据损失量。
RPO接近零。
RTO不为零,应用会中断,需要手工切换存储。切换时间较短,但由于应用中断以及复制机制都可能导致数据不一致性,因此停机时间可能远远大于存储切换时间。RPO、RTO为零。
无应用中断、无数据损失。
数据容灾性能消耗消耗系统整体(阵列、主机)性能,因此性能开销极大。消耗磁盘阵列上的CPU、内存的性能。消耗主机上的CPU、内存的性能,由于卷操作不需要内存缓冲,镜像也不是复杂计算,因此对主机的性能消耗小于3%
风险1、采用异步复制,灾难出现后,没有被复制的Archive Log 的数据将丢失;
2、采用同步复制,数据库性能将大幅下降。
1、数据从主存储复制到从存储时,链路中断,可能导致数据不一致,数据库无法启动,丢失;
2、存储Cache出现错误,将复制远端,导致两个存储都不可用。无
3.3 技术适用性分析
1. 满足业务需求上:SPICT现有重要应用全部采用Oracle RAC技术,而新开发TOPS5.0系统,也将采用Oracle RAC作为数据库,对业务连续性要求很高;因此数据要求实现绝对的零丢失,从前面的分析来看,只有Symantec运程镜像技术可以实现。
2. 方案完整性上:SPICT核心应用系统将建立应用级容灾,除了数据复制外,当灾难出现后,需要进行切换;因此,是否可以快速方便的进行切换,以及操作的难易程度十分重要。各种技术中,只有Symantec可以提供完整的数据复制和容灾切换。
a) Symantec运程镜像技术,存储出现后不需要任何切换,简单、业务零中断,适合应用级容灾;
b) 在服务器切换上,Symantec通过VCS实现零或者10分钟内完成切换,满足应用容灾需求;
c) 基于硬件的复制技术,当主存储出现故障后,需要重新挂接,切换复杂,并且挂接后数据库是否可以正常启动,没有保障;
3. 多品牌支持上:采用Symantec解决方案,其支持各主流品牌存储设备,方便在各品牌之间进行选择。
最后,SPICT选择了Symantec Storage Foundation for Oracle RAC HA/DR作为核心容灾软件,帮用户实现数据零丢失,10分钟内实现切换,满足了业务要求。
4 后续
此次SPICT基础架构建设工作已经于2009年初步完成,并且经过了严格的测试,系统可以达到以下效果:
1、单一设备故障,零切换
2、数据中心站点故障,零数据丢失、10分钟内恢复业务。
同时对SF的性能、稳定性也进行了验证,其自身非常稳定和强壮,有效的满足了企业级应用的需求。保证了核心业务系统的连续性。


站内头条

Spectra Logic 通过企业级 LTO-10 支持推进永久归档战略
2025-05-29
JetStor 推出适用于企业存储的无限数据平台即服务(DPaaS)
2025-05-29
AI推动企业需求大增,下季度SSD价格或将上涨10%
2025-05-29闪迪天花板级PCIe5.0 SSD上市,性能与能效均位于行业前沿
2025-05-29
车载数据存储需求愈来愈高,车规级UFS 4.0将变得愈发重要
2025-05-20
